Written by Dr Malcolm Campbell-Verduyn
Do I exist… on Google?
It is often said that someone or something only truly ‘exists’ when they can be located on a web search engine, and preferably within the first page of results. We have become accustomed to finding people, objects and answers to both mundane and existential questions within fractions of a second. The manners in which we search and retrieve information online are not value-free but couched in specific ideologies and interests shaping our perceptions of the world and related actions. Scrutinising the socio-technical systems underpinning web search reveals important yet often overlooked political and socio-economic processes spanning national borders, as well as opens up possibilities for resistance and change.
Various types of algorithms – computer-programmed sets of instructions – underpin the Big Data analytics providing the capacity to search, aggregate, and cross-reference large data sets in nearly real-time. A first set of algorithms enables web crawlers or ‘spiders’ to continually code and index vast volumes and varieties of web pages at velocities far greater than humans alone could ever hope to undertake. Ranking and link analysis algorithms, such as Google’s PageRank, then sort through indexed data sets relevant to the term(s) queried by search engine users, displaying lists of web pages based on the number as well as quality of other web pages linked to each result. Watch the video below to see Google’s technical explanation of how web search works.
Big Data and web search co-evolved in manners often considered to be natural, technical and apolitical. Bruno Latour reminds us, however, that “technology is society made durable”. Humans with idiosyncratic preferences and biases programmed and continually re-programme the computer codes underlying web search. By their very nature ranking algorithms are biased towards websites that are most popular amongst Internet users and tend to reinforce the visibility of already dominant actors. In ordering the vastness of the World Wide Web, search engines technologies can be understood in Latourian terms as ‘centres of calculation’ that regulate our digital experiences and related analogue practices. Several pathologies stem from such forms of algorithmic governance.
Big Data and the pathologies of algorithmic governance
Increasingly integrated into web search are ever-growing masses of ‘unstructured’ data stemming from audio files to voice recordings, as well as images and videos contained in social media posts. Sentiment analysis algorithms, for example, ‘extract’ opinions by ‘mining’ social media conversations and preferences as indicated by Facebook likes and Twitter retweets. Machine-learning algorithms underpinning evolving artificial intelligence systems like Google RankBrain are being mobilised in efforts to enable web search engines know us better than we know ourselves.
Such customised forms of web search attracted fierce critiques in the wake of the 2016 US Presidential election. Critics decried ‘filter bubbles’ that more prominently displayed web pages linking to information that users largely, or entirely, agree with rather than those potentially challenging existing understandings of the world. A related set of critiques involves ‘personalisation algorithms’ that continuously track, collect and act on the ‘digital traces’ left by our key strokes, clicks, and queries. The commodification of our Internet activities through the sale of our user data for targeted advertisements following us across services provided by the main search engine operators, from email to instant messaging, have spawned a growing unease with the manipulation and dataveillance underlying contemporary ‘surveillance capitalism’. A further critique is that such supposedly ‘smart web search’ shapes and constitutes the very realities that it purports to neutrally represent. In bringing seemingly mundane lists to life, web search is performative, like economic models and computer code more generally,
A trailer for the film The Human Face of Big Data
Another manner in which the Big Data and algorithms underlying web search subtly shape our digital experiences is by marginalising and excluding certain web pages from our search results. The exclusion of links to the web pages of opposition leaders or critical media in authoritarian states are often cited as the most evident examples of web search censorship. Yet similar activities also occur in democratic countries where web pages containing illegal material are frequently excluded from search results. Recent efforts to tweak web search algorithms in order to combat the ‘fake news’ and purposely misleading information have resulted in reduced and at times absent search results displaying the web pages deemed to be ‘radical’, such as the World Socialist Web Site.

The problem of censorship is exacerbated by the opacity that comes with private ownership. Web search algorithms are largely ‘black boxed’. Their specific coding is proprietary and accessible to neither their average users nor to the actors affected by their rankings. The search engine optimisation industry attempts to raise the ranking of certain web pages by guessing at the variables prioritised by specific search engine algorithms. Conversely, ‘Google bowling’ methods are often employed to lower the search ranking of competing web sites.
Such competitive struggles for page ranking amongst web page providers, however, are not reflected in competition between search engine operators. The global search engine market exemplifies the monopolistic tendencies of ‘digital capitalism’. Depending on where and when specifically this article is being read, Google or another single web search engine likely holds over half of the national market for web search. The remaining market shares are often held by other large Internet conglomerates, such as Baidu in China and Yahoo! in North America.

Regulating web search
Top-down initiatives to rectify the pathologies of dataveillance, censorship and opacity have included levying fines on search engine operators and enforcement of ‘right to be forgotten’ legislation that delists personal data from web search. While not unimportant, such elite efforts and their scholarly reification in what John Hobson and Leonard Seabrooke called ‘Regulatory International Political Economy’ approaches are fundamentally limited. Google has dragged out a seven year European Union investigation of its anti-competitive search practices by appealing the largest antitrust fine ever imposed by the European Commission in 2017. Accounting for the $2.7 billion fine Alphabet, Google’s parent company, still reported a $3.5 billion profit in the second quarter of 2017. One of the world’s most valuable companies, with annual profits that grew from $10 billion in 2012 to nearly $20 billion in 2016, Alphabet is amongst the largest corporate lobbyists and makes large contributions to political parties. Other major search engine operators exploit close relationships with governments, like Baidu in China. Top-down regulatory measures are difficult to impose since no one country or regulator has jurisdiction over the entire Internet. Furthermore, even if personal information is retracted from the ‘public web’, it can continue lurking in deeper and darker corners of the web.
The ‘Big Four’ search engines sort through billions of web pages on the ‘public web’, yet largely do not comb through the trillions of private company, government, and scholarly web pages located on the ‘deep’ or ‘invisible’ web. The latter can be explored through search engines specific to academic, corporate, and government registries. Meanwhile, the ‘dark web’ is designed to be difficult to navigate in order to preventing surveillance and monitoring.
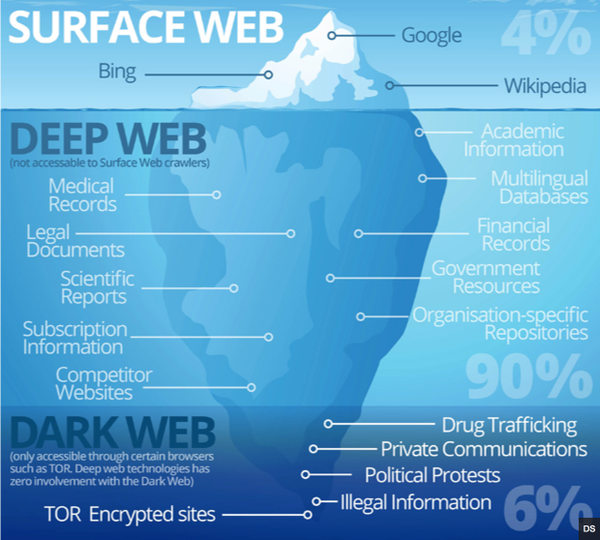
Image from Elixir of Knowledge.com
Resistance through alternative search?
While useful in revealing the pathologies of web search, opening up the ‘black boxes’ of technologies underlying web search is unlikely to eliminate our desire to locate and easily access information and entertainment on the growing number of web pages. How might our everyday web search practices navigate beyond the above pathologies? Is it possible to refine web searches in ways that suit our own interests rather than those of large and powerful actors? How might algorithmic governance be resisted?
The most prominent counter-hegemonic efforts actually reinforce the dominance of large search engines. Fairsearch is a coalition of Google’s large competitors that for a time included Microsoft, the operator of Bing. So-called ‘private’ search engines, such as Duckduckgo and Startpage, claim not to track their users yet still display results from the operators of the big search engines, their de facto allies. Search engines with overtly ethical goals also rely on the large search engines. Ecosia, for instance, contributes a large percentage of advertising revenues to tree planting programmes, with another smaller percentage going to Microsoft. Religious search engines such as SeekFind, Halalgoogling, and Jewgle all merely add ‘safe filters’ to the results of the ‘Big Four’ search engines. The most prominent alternative search engines are constrained by the very same pathologies discussed above.

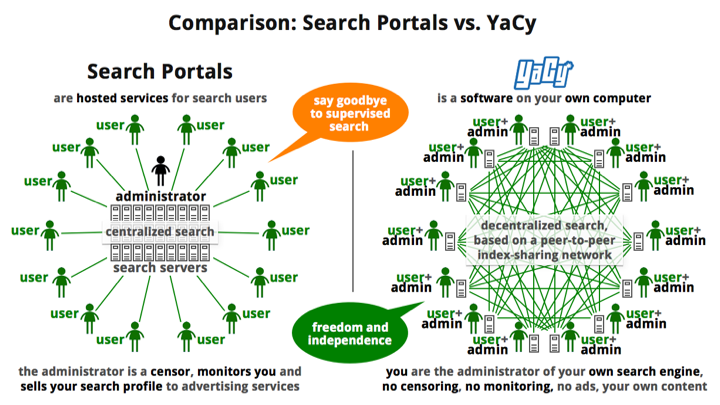
Web search crawlers and high quality programming of algorithms are expensive. Discussion of subscription-fee search engines and independent search engines, as well as the regulation of search engines as public utilities, are all regulatory ideas to avoid the pathologies associated with ‘free’ web search services. In contrast, more bottom-up initiatives, or what Hobson and Seabrooke would call Everyday International Political Economy, have involved peer-to-peer (P2P) search engines. These challenge the competitive and the proprietary underpinnings of corporate web search by building on more collaborative principles. Open-source software enables users to scrutinize and openly make cases for altering ranking algorithms within peer-production communities. In decentralising databases across the entire networks of users networks, P2P search engines like FAROO and YaCy avoid the pitfalls associated with centralised data centres that have been targeted by hackers and national intelligence agencies, as well as the criticism from NGOs like Greenpeace that such centres consume vast amounts of electricity. P2P search engines have however remained limited by relatively minuscule user networks. Moreover, whilst challenging the capitalist underpinnings of ‘alternative search’, P2P search engines reify the wider ‘culture of search’.
Other measures to subvert the objective – famously stated by Google – to “organise the world’s information” seek to ‘turn the tables’ on the large search engine operators by manipulating ranking algorithms. ‘Google bombing’, for example, involves the creation of numerous links to particular types of web pages in order for such sites to be listed higher on web search results. Often, however, the effect of such subversive actions are merely temporary, for instance with Google quickly countering efforts to link searches for “miserable failure” to George W. Bush by linking instead to ‘Google bombing’ itself.
Other acts of digital defiance seek to frustrate and obfuscate the collection of information by harnessing personal data management , as well as de-identification and anonymisation techniques. Such ‘technical fixes’, however, require considerable time and effort, which we are not all are prepared to inject into our online routines. Existing digital divides may also be furthered as only those with the necessary time and technical skills can protect their personal information online. In 2016 the English band Radiohead built anticipation for their upcoming album by deleting much of their online presence. What other manners might we undertake in challenging, resisting and seeking to move beyond the pathologies of web search?
Web Search Resources
Becker, K. and Stalder, F. eds. (2009). Deep search: The politics of search beyond Google. Vienna: Studienverlag & Transaction Publishers.
Halavais, A. (2013). Search engine society. Cambridge: Polity.
Pasquale, F. (2015). The black box society: The secret algorithms that control money and information. Cambridge: Harvard University Press.
Vaidhyanathan, S. (2012). The Googlization of everything:(and why we should worry). Berkeley and Los Angeles: University of California Press.
Campbell-Verduyn, M., Goguen, M. and Porter, T. (2017). Big Data and algorithmic governance: the case of financial practices. New Political Economy 22(2), pp. 219-236.
de Goede, M., Leander, A. and Sullivan, G. (2016). Introduction: The politics of lists. Environment and Planning D: Society and Space, 34(1), pp. 3–13.
Hansen, H., K. and Porter, T. (2017). What Do Big Data Do in Global Governance?. Global Governance: A Review of Multilateralism and International Organizations 23(1), pp. 31-42.
DECODE: a European Commission funded project exploring and piloting new technologies that give people more control over how they store, manage and use personal data generated online:
Dobusch, L. (2012), ‘Algorithm Regulation’, Governance across Borders.
Electronic Frontier Foundation

